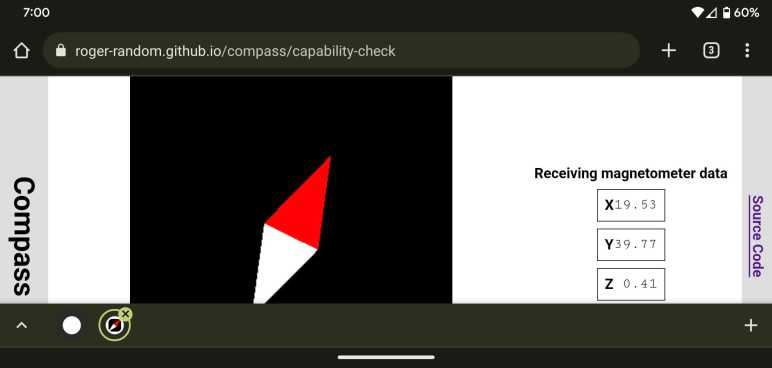
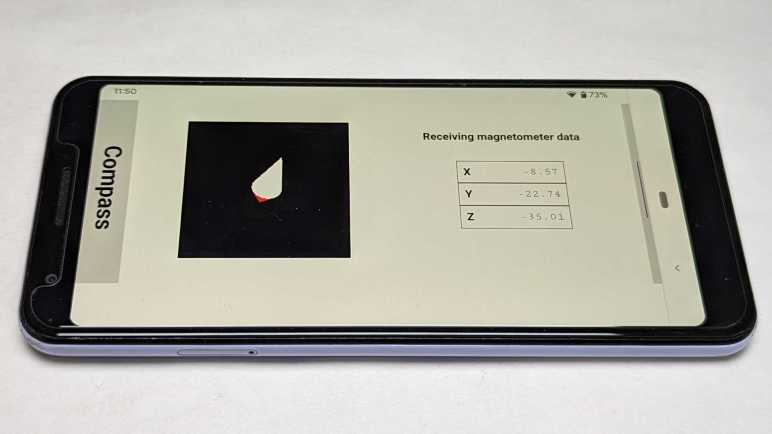
I decided to rewrite my magnetometer test app as an Angular web app. Ideally, I would end up with something more polished. But that is a secondary goal. The primary goal is to use it as a practice exercise for building web apps with Angular. Because there are definitely some adjustments to make when I can’t just use global variables and functions for everything.
My first task is to learn how to use Three.js 3D rendering library from within an Angular web app. I know this is doable from others who have written up their experience, I only have to follow their lead.
Installation
The first step is obvious: install Three.js library itself into my project.
npm install --save three
Now my Angular app could import objects from Three, but it would fail TypeScript compilation because the compiler doesn’t have type information. For that, a separate library needs to be installed. This is only used at development time, so I save it as a development-only dependency.
npm install --save-dev @types/three
HTML DOM Access via @ViewChild
Once installed I could create an Angular component using Three.js. Inside that component I could use most of the code from Three.js introduction “Creating a Scene“. One line I could not use directly is:
document.body.appendChild( renderer.domElement );
Because now I can’t just jam something to the end of my HTML document’s <BODY> element. I need to stay within the bounds of my Angular component. To do so, I name an element in my component template HTML file where I want my Three.js canvas to reside.
[...Component template HTML...]
<div #threejstarget></div>
[...Component template HTML...]
In the TypeScript code file, I can obtain a reference to this element with the @ViewChild decorator.
@ViewChild('threejstarget') targetdiv!: ElementRef;
Why the “!” suffix? If we declared the variable “targetdiv” by itself, TypeScript compiler would complain that we risk using a variable that may be null or undefined instead of its declared type. This is because TypeScript compiler doesn’t know @ViewChild will handle that initialization. We use an exclamation mark (!) suffix to silence this specific check on this specific variable without having to turn on the (generally useful) null/undefined checks in TypeScript.
(On the “To-Do” list: come back later and better understand how @ViewChild relates to similar directives @ViewChildren, @ContentChild, and @ContentChildren.)
Wait until AfterViewInit
But there are limits to @ViewChild power. Our ElementRef still starts null when our component is initialized. @ViewChild could not give us a reference until the component template view has been created. So we have to wait until the AfterViewInit stage of Angular component lifecycle before adding Three.js render canvas into our component view tree.
ngAfterViewInit() : void {
this.targetdiv.nativeElement.appendChild( this.renderer.domElement );
}
An alternative approach is to have <CANVAS> inside our component template, and attach our renderer to that canvas instead of appending a canvas created by renderer.domElement. I don’t yet understand the relevant tradeoffs between these two approaches.
Animation Callback and JavaScript ‘this‘
At this point I had a Three.js object onscreen, but it did not animate even though my requestAnimationFrame() callback function was being called. A bit of debugging pointed to my mistaken understanding of how JavaScript handles an object’s “this” reference. My animation callback was getting called in a context where it was missing a “this” reference back to my Angular component, and thus unable to advance the animation sequence.
requestAnimationFrame(this.renderNeedle);
One resolution to this issue (JavaScript is very flexible, there are many other ways) is to declare a callback that has an appropriate “this” reference saved within it for use.
requestAnimationFrame((timestamp)=>this.renderNeedle(timestamp));
That’s a fairly trivial problem and it was my own fault. There are lots more to learn about animating and Angular from others online, like this writeup about an animated counter.
Increase Size Budget
After that work I had a small Three.js animated object in my Angular application. When I run “ng build” at that point, I would see a warning:
Warning: bundle initial exceeded maximum budget. Budget 500.00 kB was not met by 167.17 kB with a total of 667.17 kB.
An empty Angular application already weighs in at over 200kB. Once we have Three.js in the deployment bundle, that figure ballooned by over 400kB and exceeded the default warning threshold of 500kB. This is a sizable increase, but thanks to optimization tools in the Angular build pipeline, this is actually far smaller than my simple test app. My test app itself may be tiny, but it downloaded the entire Three.js module from a CDN (content distribution network) and that file three.module.js is over a megabyte (~1171kB) in size. By that logic this is the better of two options, we just have to adjust the maximumWarning threshold in angular.json accordingly.
My first draft used a fixed-size <DIV> as my Three.js target, which is easy but wouldn’t be responsive to different browser situations. For that I need to learn how to use CSS layout for my target <DIV>
Source code for this project is publicly available on GitHub