The best part about learning a new technology today is the fact that, once armed with a few key terminology, a web search can unlock endless resources online. Some of which are even free! Such was the case after I looked over OpenAI Gym on its own: I searched for an introductory reinforcement learning project online and found several to choose from. I started with this page which uses the “Taxi” environment of OpenAI Gym and, within a few lines of Python code, implemented basic Q-Learning agent that can complete the task within 1000 episodes.
I had previously read the Wikipedia page on Q-Learning, but a description suitable for an encyclopedia entry is not always straightforward to put into code. For example, Wikipedia described learning rate is a value from 0 to 1 plus what it means when it is at the extremes of 0 or 1. But it doesn’t give any guidance on what kind of values are useful in real world examples. The tutorial used 0.618 and while there isn’t enough information on why that value was chosen, it served as a good enough starting point. For this and more related reasons, it was good to have a simple implementation.
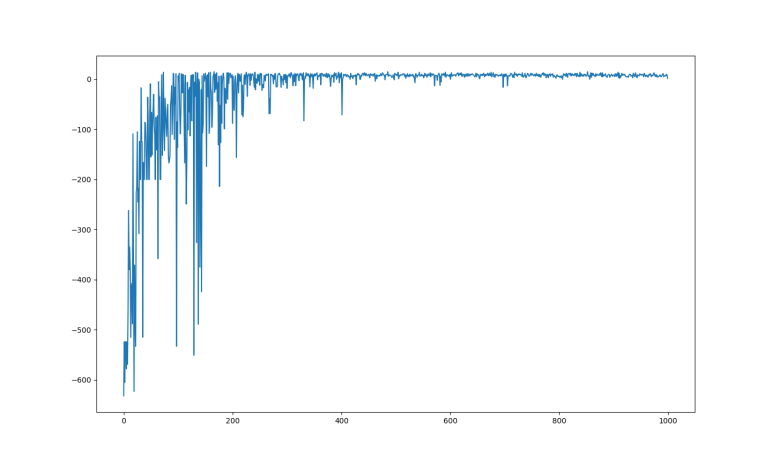
After I got it running, it was time to start poking around to learn more. The first question was how fast the algorithm learned to solve the problem, and for that I wanted to plot the cumulative evaluation function reward against iterations. This was trivial with help of PyPlot and I obtained the graph at the top of this post. We can see a lot of learning progress within the first 100 episodes. There’s a mysterious degradation in capability around 175th episode, but the system mostly recovered by 200. After that, there were diminishing returns until about 400 and the agent made no significant improvements after that point.
This simple algorithm used an array that could represent all 500 states of the environment. With six possible actions, it was an array with 3000 entries initially filled with zero. I was curious how long it took for the entire problem space to be explored, and the answer seems to be roughly 50 episodes before there were 2400 nonzero entries and it never exceeded 2400. This was far faster than I had expected to take to explore 2400 states, and it was also a surprise that 600 entries in the array were never used.
What did those 600 entries represent? With six possible actions, it implies there are 100 unreachable states of the environment. I thought I’d throw that array into PyPlot and see if anything jumped out at me:
My mind is at a loss as to how to interpret this data. But I don’t know how important it is to understand right now – this is an environment whose entire problem space can be represented in memory, using discrete values, and these are luxuries that quickly disappear as problems get more complex. The real world is not so easily classified into discrete states, and we haven’t even involved neural networks yet. The latter is referred to as DQN (Deep Q-learning Network?) and is still yet to come.
The code I wrote for this exercise is available here.
