After deciding to move data processing off of the microcontroller, it would make sense to repeat my exercise with an even cheaper microcontroller. But there aren’t a lot of WiFi-capable microcontrollers cheaper than an ESP8266. So I looked at the associated decision to communicate via MQTT instead, because removing requirement for an InfluxDB client library meant opening up potential for other development platforms.
I thought it’d be interesting to step up to ESP8266’s big brother, the ESP32. I could still develop with the Arduino platform with an ESP32 but for the sake of practice I’m switching to Espressif’s ESP-IDF platform. There isn’t an InfluxDB client library for ESP-IDF, but it does have a MQTT library.
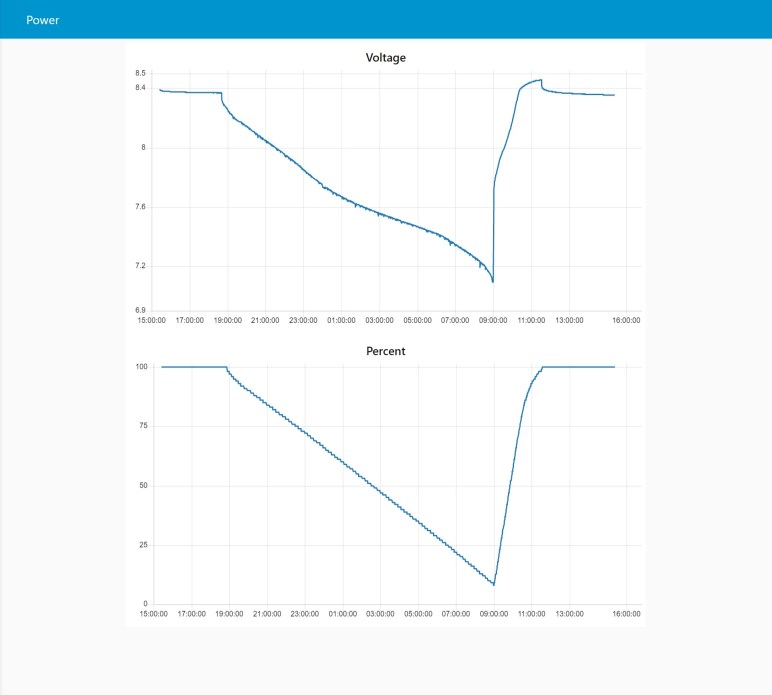
ESP32 has more than one ADC channel, and they are more flexible than the single channel on board the ESP8266. However, that is not a motivate at the moment as I don’t have an immediate use for that advantage. I thought it might be interesting to measure current as well as voltage. Unfortunately given how noisy my amateur circuits have proven to be, I doubt I could build a circuit that can pick up the tiny voltage drop across a shunt resistor. Best to delegate that to a dedicated module designed by people who know what they are doing.
One reason I wanted to use an ESP32 is actually the development board. My Wemos D1 Mini clone board used a voltage regulator I could not identify, so I powered it with a separate MP1584EN buck converter module. In contrast, the ESP32 board I have on hand has a regulator clearly marked as an AMS1117. The datasheet for AMS1117 indicated a maximum input voltage of 15V. Since I’m powering my voltage monitor with a lead-acid battery array that has a maximum voltage of 14.4V, in theory I could connect it directly to the voltage input pin on this module.
In practice, connecting ~13V to this dev board gave me an audible pop, a visible spark, and a little cloud of smoke. Uh-oh. I disconnected power and took a closer look. The regulator now has a small crack in its case, surrounded by shiny plastic that had briefly turned liquid and re-solidified. I guess this particular regulator is not genuine AMS1117. It probably works fine converting 5V to 3.3V, but it definitely did not handle a maximum of 15V like real AMS1117 chips are expected to do.
Fortunately, ESP32 development boards are cheap, counterfeit regulators and all. So I chalked this up to lesson learned and pulled another board out of my stockpile. This time voltage regulation is handled by an external MP1584EN buck converter. I still want to play with an ESP32 for its digital output pins.